███████╗███╗ ███╗ █████╗ ████████╗██╗██╗ ██╗ ██╔════╝████╗ ████║██╔══██╗╚══██╔══╝██║╚██╗██╔╝ █████╗ ██╔████╔██║███████║ ██║ ██║ ╚███╔╝ ██╔══╝ ██║╚██╔╝██║██╔══██║ ██║ ██║ ██╔██╗ ███████╗██║ ╚═╝ ██║██║ ██║ ██║ ██║██╔╝ ██╗ ╚══════╝╚═╝ ╚═╝╚═╝ ╚═╝ ╚═╝ ╚═╝╚═╝ ╚═╝
WORKFLOW-FIRST DATA PIPELINES IN PYTHON.
The flow in ematix-flow is the workflow. Group jobs into a named workflow with a DAG between them, then declare WHEN it fires — cron, upstream completion, message arrival, or any AND‑conjunction of those. Rust + Apache Arrow under the hood. Watermarks, schema evolution, restart-safe state, at-least-once delivery — built in. No extra scheduler service to deploy.
User Guide
Install, connections, pipelines, modes, scheduling, streaming, stream processing, CLI. Each chapter is a copy-paste-runnable example.
Specs & Benchmarks
Why ematix-flow exists, what's shipped, TPC-H numbers (1.75× DuckDB, 2.77× Polars, 13.4× PySpark geomean), and how it stacks up against the field.
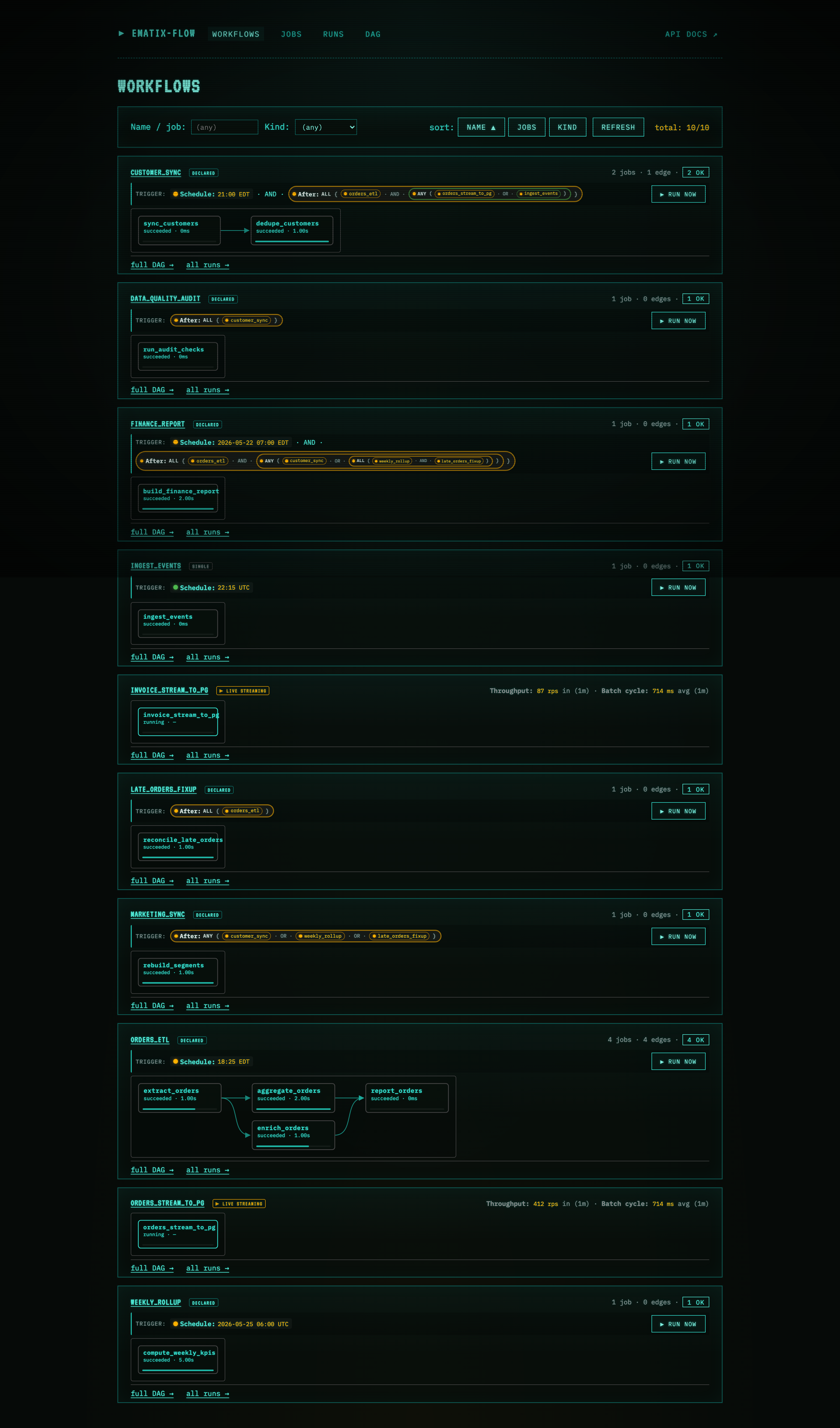
Workflows tab ships with
flow web — one card per workflow, with the
member jobs laid out as an inline SVG flowchart. Arrows show
DAG dependencies; bar width on each node encodes its latest-run
duration. Click any node to focus the full DAG view on that
job. Jobs without a workflow show up as
kind: single workflow-of-one cards.
from ematix_flow import ematix, ManagedTable, Annotated, BigInt, Text, pk
@ematix.connection
class warehouse:
kind = "postgres"
url = "${WAREHOUSE_URL}"
class OrdersExtracted(ManagedTable):
__schema__ = "analytics"; __tablename__ = "orders_extracted"
order_id: Annotated[BigInt, pk()]
customer_id: BigInt
amount_cents: BigInt
class OrdersEnriched(ManagedTable):
__schema__ = "analytics"; __tablename__ = "orders_enriched"
order_id: Annotated[BigInt, pk()]
amount_bucket: Text
class OrdersByCustomer(ManagedTable):
__schema__ = "analytics"; __tablename__ = "orders_by_customer"
customer_id: Annotated[BigInt, pk()]
order_count: BigInt
# Jobs declare their DAG position with depends_on.
@ematix.job(name="extract_orders",
target=OrdersExtracted, target_connection="warehouse",
mode="merge", keys=("order_id",))
def extract_orders(conn):
return "SELECT order_id, customer_id, amount_cents FROM raw.orders"
@ematix.job(name="enrich_orders",
target=OrdersEnriched, target_connection="warehouse",
mode="merge", keys=("order_id",),
depends_on=["extract_orders"])
def enrich_orders(conn):
return "SELECT order_id, CASE WHEN amount_cents < 10000 THEN 'small' ELSE 'large' END AS amount_bucket FROM analytics.orders_extracted"
@ematix.job(name="aggregate_orders",
target=OrdersByCustomer, target_connection="warehouse",
mode="merge", keys=("customer_id",),
depends_on=["extract_orders"])
def aggregate_orders(conn):
return "SELECT customer_id, COUNT(*) AS order_count FROM analytics.orders_extracted GROUP BY 1"
# Workflow declares the trigger — fires when upstream_workflow has
# succeeded AND the 21:00 NY tick has reached, since last self-run.
ematix.workflow(
name="orders_etl",
triggered_by=["upstream_workflow"],
schedule="0 21 * * *",
timezone="America/New_York",
jobs=["extract_orders", "enrich_orders", "aggregate_orders"],
)ematix-flow. Surfaces are stabilizing; minor APIs may still shift before beta.